


Running powerful AI on your smartphone isn’t just a hardware problem — it’s a model architecture problem. Most state-of-the-art vision encoders are enormous, and when you trim them down to fit on an edge device, they lose the capabilities that made them useful in the first place. Worse, specialized models tend to excel at one type of task — image classification, say, or scene segmentation — but fall apart when you ask them to do something outside their lane.
Meta’s AI research teams are now proposing a different path. They introduced the Efficient Universal Perception Encoder (EUPE): a compact vision encoder that handles diverse vision tasks simultaneously without needing to be large.
The Core Problem: Specialists vs. Generalists
To understand why EUPE matters, it helps to understand how vision encoders work and why specialization is a problem.
A vision encoder is the part of a computer vision model that converts raw image pixels into a compact representation — a set of feature vectors — that downstream tasks (like classification, segmentation, or answering questions about an image) can use. Think of it as the ‘eyes’ of an AI pipeline.

Modern foundation vision encoders are trained with specific objectives, which gives them an edge in particular domains. For example:
CLIP and SigLIP 2 are trained on text-image pairs. They’re strong at image understanding and vision-language modeling, but their performance on dense prediction tasks (which require spatially precise, pixel-level features) often falls below expectations.
DINOv2 and its successor DINOv3 are self-supervised models that learn exceptional structural and geometric descriptors, making them strong at dense prediction tasks like semantic segmentation and depth estimation. But they lack satisfactory vision-language capabilities.
SAM (Segment Anything Model) achieves impressive zero-shot segmentation through training on massive segmentation datasets, but again falls short on vision-language tasks.
For an edge device — a smartphone or AR headset — that needs to handle all of these task types simultaneously, the typical solution is to deploy multiple encoders at once. That quickly becomes compute-prohibitive. The alternative is accepting that a single encoder will underperform in several domains.
Previous Attempts: Why Agglomerative Methods Fell Short on Efficient Backbones
Researchers have tried to combine the strengths of multiple specialist encoders through a family of methods called agglomerative multi-teacher distillation. The basic idea: train a single student encoder to simultaneously mimic several teacher models, each of which is a domain expert.
AM-RADIO and its follow-up RADIOv2.5 are perhaps the most well-known examples of this approach. They showed that agglomerative distillation can work well for large encoders — models with more than 300 million parameters. But the EUPE research demonstrates a clear limitation: when you apply the same recipe to efficient backbones, the results degrade substantially. RADIOv2.5-B, the ViT-B-scale variant, has significant gaps compared to domain experts on dense prediction and VLM tasks.
Another agglomerative method, DUNE, merges 2D vision and 3D perception teachers through heterogeneous co-distillation, but similarly struggles at the efficient backbone scale.
The root cause, the research team argue, is capacity. Efficient encoders simply don’t have enough representational capacity to directly absorb diverse feature representations from multiple specialist teachers and unify them into a universal representation. Trying to do so in one step produces a model that is mediocre across the board.
EUPE’s Answer: Scale Up First, Then Scale Down
The key insight behind EUPE is a principle named ‘first scaling up and then scaling down.‘
Instead of distilling directly from multiple domain-expert teachers into a small student, EUPE introduces an intermediate model: a large proxy teacher with enough capacity to unify the knowledge from all the domain experts. This proxy teacher then transfers its unified, universal knowledge to the efficient student through distillation.
The full pipeline has three stages:
Stage 1 — Multi-Teacher Distillation into the Proxy Model. Multiple large foundation encoders serve as teachers simultaneously, processing label-free images at their native resolutions. Each teacher outputs a class token and a set of patch tokens. The proxy model — a 1.9B parameter model trained with 4 register tokens — is trained to mimic all teachers at once. The selected teachers are:
PEcore-G (1.9B parameters), selected as the domain expert for zero-shot image classification and retrieval
PElang-G (1.7B parameters), which the research team found is crucial for vision-language modeling, particularly OCR performance
DINOv3-H+ (840M parameters), selected as the domain expert for dense prediction
To stabilize training, teacher outputs are normalized by subtracting the per-coordinate mean and dividing by the standard deviation, computed once over 500 iterations before training begins and kept fixed thereafter. This is deliberately simpler than the complex PHI-S normalization used in RADIOv2.5, and avoids the cross-GPU memory overhead of computing normalization statistics on-the-fly.
Stage 2 — Fixed-Resolution Distillation into the Efficient Student. With the proxy model now serving as a single universal teacher, the target efficient encoder is trained at a fixed resolution of 256×256. This fixed resolution makes training computationally efficient, allowing a longer learning schedule: 390,000 iterations with a batch size of 8,192, cosine learning rate schedule, a base learning rate of 2e-5, and weight decay of 1e-4. Standard data augmentation applies: random resized cropping, horizontal flipping, color jittering, Gaussian blur, and random solarization. For the distillation loss, the class token loss uses cosine similarity, while the patch token loss combines cosine similarity (weight α=0.9) and smooth L1 loss (weight β=0.1). Adapter head modules — 2-layer MLPs — are appended to the student to match each teacher’s feature dimension. If student and teacher patch token spatial dimensions differ, 2D bicubic interpolation is applied to align them.
Stage 3 — Multi-Resolution Finetuning. Starting from the Stage 2 checkpoint, the student undergoes a shorter finetuning phase using an image pyramid of three scales: 256, 384, and 512. The student and the proxy teacher independently and randomly select one scale per iteration — so they may process the same image at different resolutions. This forces the student to learn representations that generalize across spatial granularities, accommodating downstream tasks that operate at various resolutions. This stage runs for 100,000 iterations at a batch size of 4,096 and base learning rate of 1e-5. It is intentionally shorter because multi-resolution training is computationally costly — one iteration in Stage 3 takes roughly twice as long as in Stage 2.
Training Data. All three stages use the same DINOv3 dataset, LVD-1689M, which provides balanced coverage of visual concepts from the web alongside high-quality public datasets including ImageNet-1k. The sampling probability from ImageNet-1k is 10%, with the remaining 90% from LVD-1689M. In an ablation study, training on LVD-1689M consistently outperformed training on MetaCLIP (2.5B images) on nearly all benchmarks — despite MetaCLIP being approximately 800M images larger — indicating higher data quality in LVD.
An Important Negative Result: Not All Teachers Combine Well
One of the more practically useful findings concerns teacher selection. Intuitively, adding more strong teachers should help. But the research team found that including SigLIP2-G alongside PEcore-G and DINOv3-H+ substantially degrades OCR performance. At the proxy model level, TextVQA drops from 56.2 to 53.2; at the ViT-B student level, it drops from 48.6 to 44.8. The research teams’ hypothesis: having two CLIP-style models (PEcore-G and SigLIP2-G) in the teacher set simultaneously causes feature incompatibility. PElang-G, a language-focused model derived from PEcore-G through alignment with language models, proved a far better complement — improving OCR and general VLM performance without sacrificing image understanding or dense prediction.
What the Numbers Say
The ablation studies validate the three-stage design. Distilling directly from multiple teachers to an efficient student (“Stage 2 only”) yields poor VLM performance, especially on OCR-type tasks, and poor dense prediction. Adding Stage 1 (the proxy model) significantly improves VLM tasks — TextVQA rises from 46.8 to 48.3, and Realworld from 53.5 to 55.1 — but still lags on dense tasks. Stage 1+3 (skipping Stage 2) gives the strongest dense prediction results (SPair: 53.3, NYUv2: 0.388) but leaves VLM gaps and is costly to run for a full schedule. The full three-stage pipeline achieves the best overall balance.
On the main ViT-B benchmark, EUPE-ViT-B consistently stands out:
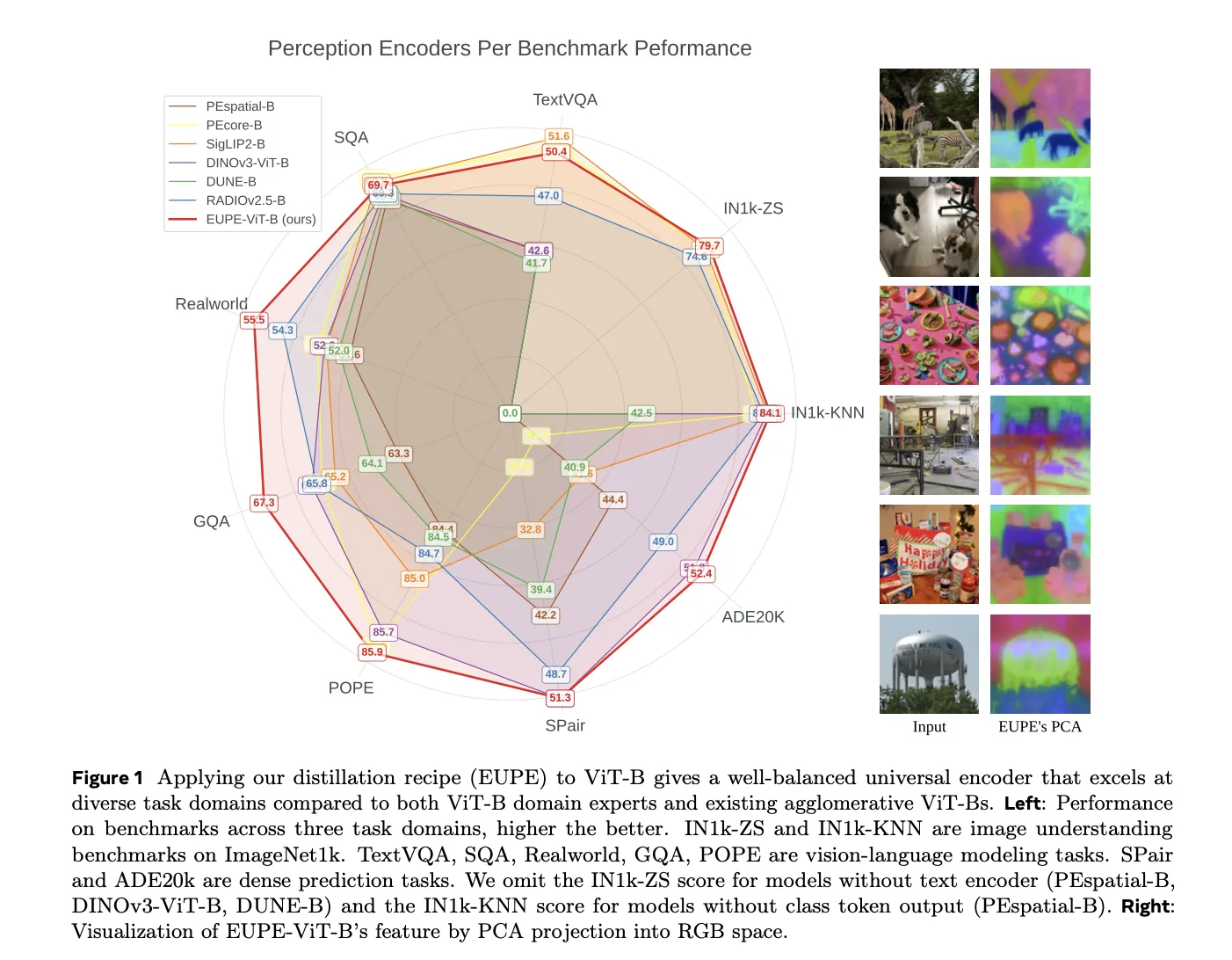
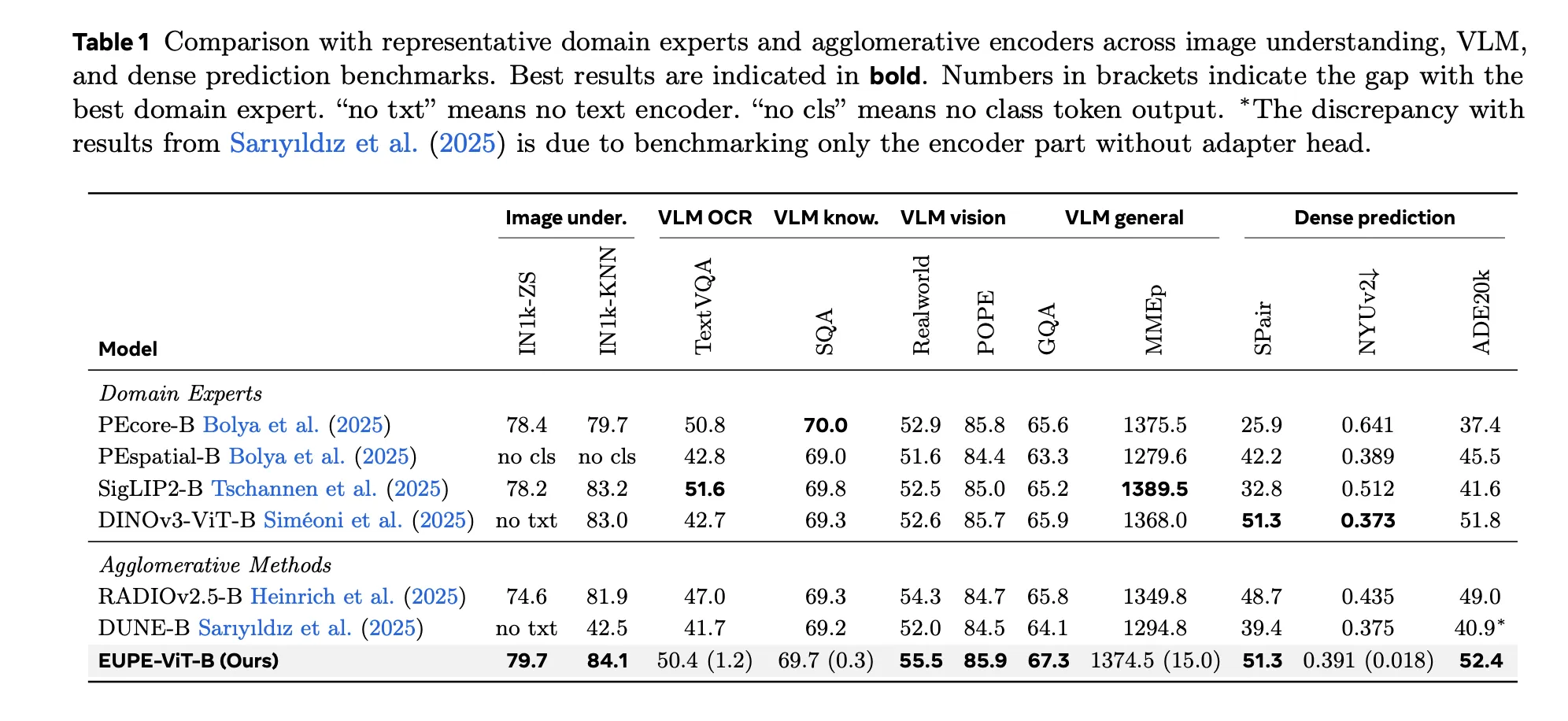
Image understanding: EUPE achieves 84.1 on IN1k-KNN, outperforming PEcore-B (79.7), SigLIP2-B (83.2), and DINOv3-ViT-B (83.0). On IN1k-ZS (zero-shot), it scores 79.7, outperforming PEcore-B (78.4) and SigLIP2-B (78.2).
Dense prediction: EUPE achieves 52.4 mIoU on ADE20k, outperforming the dense prediction expert DINOv3-ViT-B (51.8). On SPair-71k semantic correspondence, it scores 51.3, matching DINOv3-ViT-B.
Vision-language modeling: EUPE outperforms both PEcore-B and SigLIP2-B on RealworldQA (55.5 vs. 52.9 and 52.5) and GQA (67.3 vs. 65.6 and 65.2), while staying competitive on TextVQA, SQA, and POPE.
Vs. agglomerative methods: EUPE outperforms RADIOv2.5-B and DUNE-B on all VLM tasks and most dense prediction tasks by significant margins.
What the Features Actually Look Like
The research also includes qualitative feature visualization using PCA projection of patch tokens into RGB space — a technique that reveals the spatial and semantic structure an encoder has learned. The results are telling:
PEcore-B and SigLIP2-B patch tokens contain semantic information but are not spatially consistent, leading to noisy representations.
DINOv3-ViT-B has highly sharp, semantically coherent features, but lacks fine-grained discrimination (food and plates end up with similar representations in the last row example).
RADIOv2.5-B features are overly sensitive, breaking semantic coherence — for example, black dog fur merges visually with the background.
EUPE-ViT-B combines semantic coherence, fine granularity, complex spatial structure, and text awareness simultaneously — capturing the best qualities across all domain experts at once.
A Full Family of Edge-Ready Models
EUPE is a complete family spanning two architecture types:
ViT family: ViT-T (6M parameters), ViT-S (21M), ViT-B (86M)
ConvNeXt family: ConvNeXt-Tiny (29M), ConvNeXt-Small (50M), ConvNeXt-Base (89M)
All models are under 100M parameters. Inference latency is measured on iPhone 15 Pro CPU via ExecuTorch-exported models. At 256×256 resolution: ViT-T runs in 6.8ms, ViT-S in 17.1ms, and ViT-B in 55.2ms. The ConvNeXt variants have lower FLOPs than ViTs of similar size, but do not necessarily achieve lower latency on CPU — because convolutional operations are often less efficient on CPU architecture compared to the highly optimized matrix multiplication (GEMM) operations used in ViTs.
For the ConvNeXt family, EUPE consistently outperforms the DINOv3-ConvNeXt family of the same sizes across Tiny, Small, and Base variants on dense prediction, while also unlocking better VLM capability — particularly for OCR and vision-centric tasks — that DINOv3-ConvNeXt entirely lacks.
Key Takeaways
One encoder to rule them all. EUPE is a single compact vision encoder (under 100M parameters) that matches or outperforms specialized domain-expert models across image understanding, dense prediction, and vision-language modeling — tasks that previously required separate, dedicated encoders.
Scale up before you scale down. The core innovation is a three-stage “proxy teacher” distillation pipeline: first aggregate knowledge from multiple large expert models into a 1.9B parameter proxy, then distill from that single unified teacher into an efficient student — rather than directly distilling from multiple teachers at once.
Teacher selection is a design decision, not a given. Adding more teachers doesn’t always help. Including SigLIP2-G alongside PEcore-G degraded OCR performance significantly. PElang-G turned out to be the right VLM complement — a finding with direct practical implications for anyone building multi-teacher distillation pipelines.
Built for real edge deployment. The full EUPE family spans six models across ViT and ConvNeXt architectures. The smallest, ViT-T, runs in 6.8ms on iPhone 15 Pro CPU. All models are exported via ExecuTorch and available on Hugging Face — ready for on-device integration, not just benchmarking.
Data quality beats data quantity. In ablation experiments, training on LVD-1689M outperformed training on MetaCLIP across nearly all benchmarks — despite MetaCLIP containing roughly 800 million more images. A useful reminder that bigger datasets don’t automatically mean better models.
Check out the Paper, Model Weight and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Be the first to comment