


In brief
- Five frontier AI models disagreed on 67% of 1,000 real-world fact-check claims.
- Unanimous agreement happened on only 328 claims.
- At 0.639 Krippendorff’s alpha, the models fall below the 0.8 reliability threshold.
Ask five of the world’s most advanced AI systems whether a statement is true, and two-thirds of the time, at least one will give you a different answer. That’s the finding of a new study published this month by researcher Kosta Jordanov at Lenz Research.
The study gave GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro with Search, and Sonar Pro the same 1,000 real-world fact-check claims submitted by actual users. The models had to pick one of four labels: true, mostly true, misleading, or false.
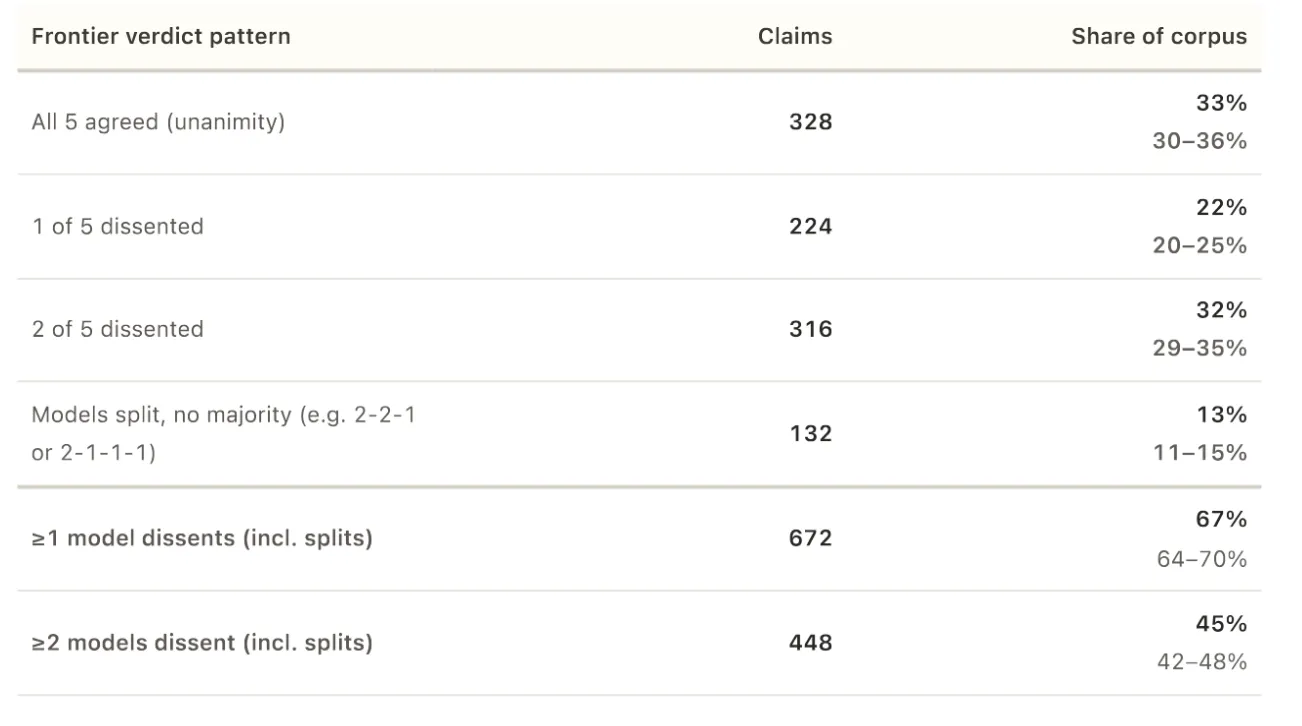
On 672 out of 1,000 claims, at least one model broke from the majority. In 34% of cases, the disagreement was severe: one model called a claim true while another called it false.

“These aren’t benchmark items with public answer keys—they’re claims real users submitted for verification to a fact-checking platform,” the study reads. “Only one verdict bucket can be correct per claim, so any disagreement among the panel means at least one model’s verdict is label-inconsistent under this 4-bucket rubric.”
Previous studies on AI hallucination have shown that chatbots invent facts. That’s one problem. This is a different one. The models aren’t necessarily making things up, they just can’t agree on basic factual judgments about the same material.
The research used a setup that makes it harder for the AI companies to explain away. Instead of pulling claims from standard test sets—the kind that often leak into training data—the researchers used claims submitted by real people to Lenz’s fact-checking platform. “Most of these claims are unlikely to appear in any training corpus with a gold label attached—there’s no canonical answer key to pattern-match against, no benchmark leaderboard to anchor to,” the paper notes.
The statistical measure of agreement, called Krippendorff’s alpha, came in at 0.639 on a scale where 1.0 means perfect agreement and 0 means random chance. The study says this indicates “nontrivial but limited agreement.” “The models’ verdicts are structured rather than random, but not consistent enough to treat the panel as a single interchangeable judge,” researchers note. Researchers generally consider anything below 0.8 to be weak.
When all five models did agree—which happened on only 328 out of 1,000 claims—they almost never agreed that something was misleading or mostly true. Just four claims received a unanimous “misleading” verdict. Zero received unanimous “mostly true.”
The researchers provided example claims where the AI models showed the most divergence, including “The World Bank’s active portfolio in Nigeria stands an over $16.4 billion as of 2025.” ChatGPT 5.4 said it was “mostly true” while Gemini 3 Pro called it “false” and its sister model Gemini 3 Pro + Search rated it “misleading.”
In another example, the models were provided with the claim: “Donald Trump said that an attack on Iran was postponed at the request of Gulf Allies.” GPT-5.4 said it was false, Claude Opus 4.7 called it mostly true, Gemini 3 Pro said false, and Gemini 3 Pro + Search rated it true.
“The panel converges on definitive verdicts; the middle of the rubric is where it fractures,” the researchers found. Unanimity only happened at the extremes: either the claim was definitely true or definitely false.
This matters because people are increasingly turning to AI systems for fact-checking. If you paste a claim from a news article into ChatGPT, Claude, or Gemini, you might get three different answers. Which one do you trust?
AI companies love to tell you their models are getting more accurate. They publish benchmark scores showing steady improvement. But the Lenz study tested these models on the kind of jagged, ambiguous claims that real humans actually argue about—and found that the models argue too.
The paper is careful to point this out. “A majority of frontier models is not ground truth. The majority verdict is sometimes wrong; an individual dissenting model is sometimes right. We use the majority as a structural reference point for measuring disagreement, not as a stand-in for correctness.”
There’s a deeper problem buried in the numbers. When models disagree, at least one of them must be wrong—the study calls a model’s verdict “label-inconsistent under this 4-bucket rubric.” There’s no tie-breaker mechanism, no appeals court. Recent reporting on AI reliability has raised similar alarms.
On the 328 claims where all five models agreed, zero received a unanimous “mostly true.” The nuance bucket emptied out completely. If AI models can only find consensus at the extremes, can they be trusted as fact checkers at all?
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.

Be the first to comment